- News and insights
- Blog
How Object Detectors learn
In this post, we are going to try to answer the following two question: what is object detection? and how do object detectors learn to detect objects?
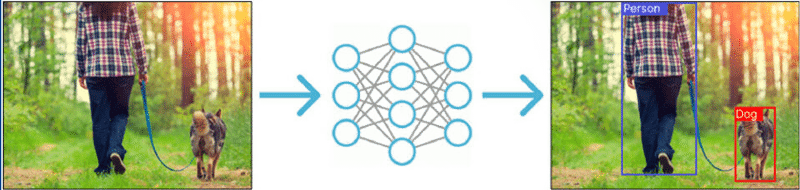
Object detection is a very well-studied subject, which is used in many useful and exciting applications today, such as for tracking objects (speed, position etc.), in surveillance system, for anomaly detection, for sorting and filtering objects on assembly lines, for counting (e.g. how many people are visiting the central station every day and how many cars are passing by this bridge or intersection) and many others.
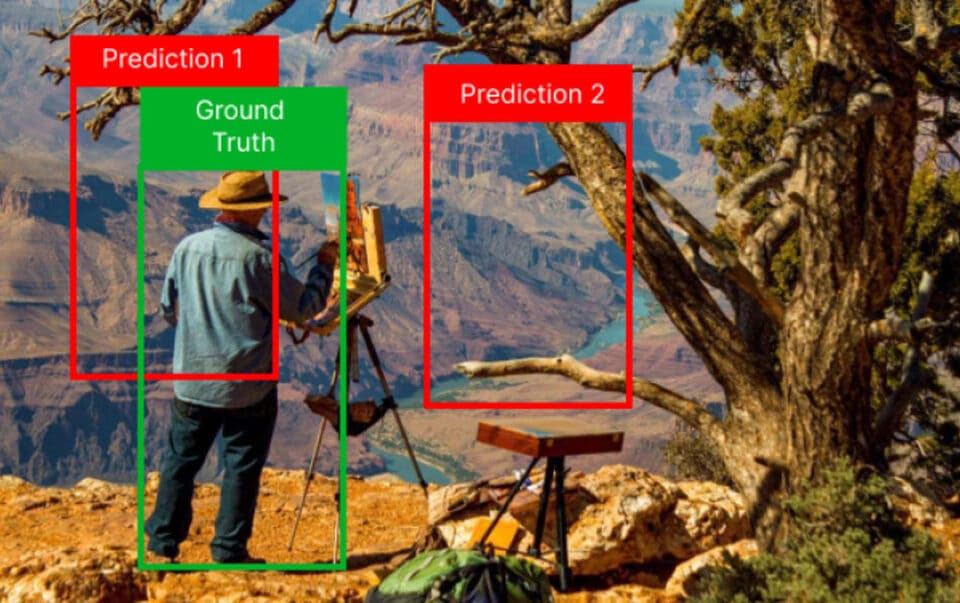
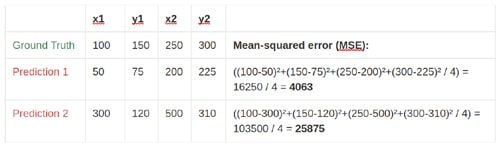
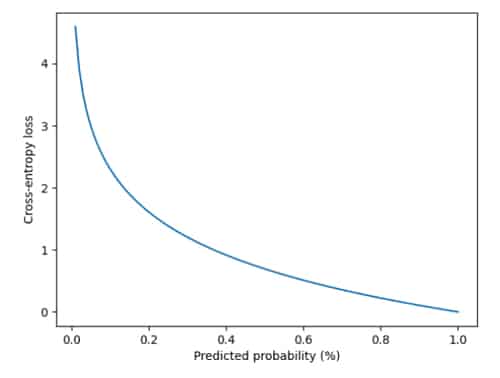
One of the key ideas about how object detectors, and really any type of deep learning model, learns is loss functions. The loss function is the very thing which defines what deep learning models such as object detectors will learn during training. So this is what we are going to cover in this post. More specifically, we are going to take a look at the two main loss functions of object detectors called bounding box regression and cross-entropy loss.
Just for clarification, loss functions are sometimes also being referred to as objective functions or cost functions. However, in this post we will stick to loss functions.