- News and insights
- Blog
Computer Vision – image classification and object detection
In this blogpost we will first examine classic computer vision. Then we will move into modern computer vision, which uses deep learning to recognize and locate objects. And lastly, we’ll also cover how to train the deep learning networks
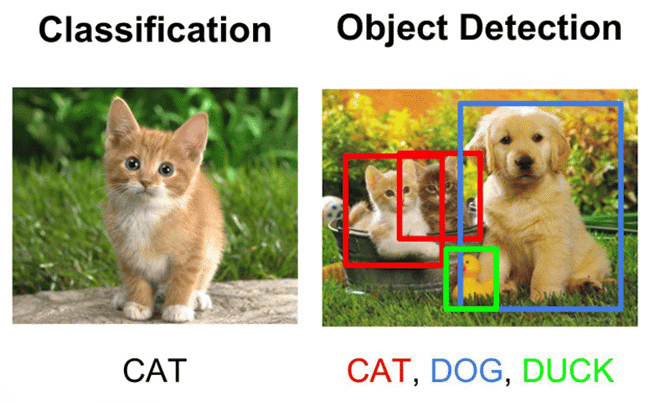
We cover both image classification (is there a cat in the picture?), and object detection (where is the cat in the picture), which is a more advanced form of image classification.
Take a look around the room and notice the different objects. You may see a desk, a lamp, or a chair. For a human, it’s easy to recognize and distinguish between these objects, but for a computer, this is a much more complicated endeavour. Since the 70’s computer scientists have worked computer systems that can ‘see’. While they’ve made some advancements towards this goal, the real breakthroughs have happened in the last couple of decades with the introduction of deep neural networks, into the field of computer vision. This has enabled computers to see, recognize and understand objects at an unprecedented level.
These advancements have opened up a massive space of opportunities in many different industries, from self-driving cars, to quality assurance in production lines, to detection of rust in wheat.